忘记炒作;人工智能在哪里创造真正的价值?让我们利用边缘计算来利用人工智能的力量,打造更智能、快速、安全、可靠的用户体验。
推荐无处不在,每个人都知道,使网络体验更加个性化可以使其更具吸引力和成功。 我的亚马逊主页知道我喜欢家居用品、厨具,现在还喜欢夏季服装:
如今,大多数平台都让您在快速或个性化之间做出选择。在 fastly,我们认为您和您的用户应该同时拥有两者。 如果每次你的网络服务器生成一个页面,它只适合一个最终用户,你就无法从缓存中受益,而这正是像 fastly 这样的边缘网络做得很好的地方。
那么如何从边缘缓存中受益,同时使内容个性化? 我们之前写过很多关于如何将复杂的客户端请求分解为多个较小的、可缓存的后端请求的文章,您可以在我们的开发人员中心的个性化主题中找到教程、代码示例和演示。
但是,如果您想更进一步并在边缘生成个性化数据该怎么办? “边缘”——处理您网站流量的 fastly 服务器,是距离最终用户最近的点,且仍在您的控制范围内。一个制作特定于某个用户的内容的好地方。
“为你”用例
产品推荐本质上是短暂的,特定于单个用户,并且可能会经常变化。 但它们也不需要持续存在——我们通常不需要知道我们向每个人推荐了什么,只需要知道特定算法是否比其他算法实现了更好的转换。 一些推荐算法需要访问大量的状态数据,例如哪些用户与您最相似以及他们的购买或评分历史记录,但通常这些数据很容易批量预生成。
基本上,生成推荐通常不会创建事务,不需要数据存储中的任何锁,并利用可从当前用户会话立即可用的输入数据,或在离线构建过程中创建的输入数据。
听起来我们可以在边缘生成推荐!
一个现实世界的例子
我们来看看纽约大都会艺术博物馆的网站:
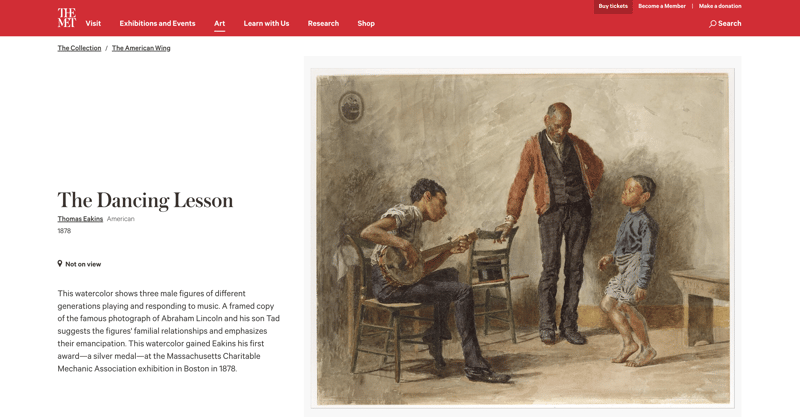
大都会博物馆藏品中的 500,000 件左右的藏品中,每一件都有一个页面,上面有图片和相关信息。 它还具有相关对象的列表:
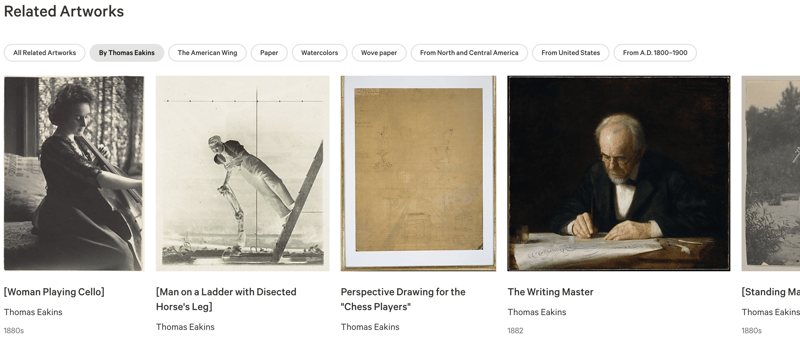
这似乎使用了相当简单的分面系统来生成这些关系,向我展示同一艺术家的其他艺术品,或博物馆同一侧翼中的其他物体,或者也是由纸制成或起源于同一时期的其他物体.
这个系统的好处(从开发人员的角度来看!)是,由于它仅基于一个输入对象,因此可以预先生成到页面中。
如果我们想通过一系列基于最终用户浏览大都会网站时的个人浏览历史记录的推荐来增强这一点,而不仅仅是基于这个对象,该怎么办?
添加个性化推荐
我们可以通过很多方法来做到这一点,但我想尝试使用语言模型,因为人工智能现在正在发生,而且它与大都会现有的相关艺术品机制似乎工作的方式确实不同。 计划是这样的:
- 下载大都会博物馆的开放获取收藏数据集。
- 通过语言模型运行它以创建向量嵌入 - 适合机器学习任务的数字列表。
- 为生成的 50 万个向量(代表大都会艺术博物馆的艺术品)构建一个高性能相似性搜索引擎,并将其加载到 kv 存储中,以便我们可以从 fastly compute 中使用它。
完成所有这些后,当您浏览大都会博物馆的网站时,我们应该能够:
- 在 cookie 中跟踪您访问过的艺术品。
- 查找这些艺术品对应的向量。
- 计算代表您的浏览兴趣的平均向量。
- 将其插入我们的相似性搜索引擎以查找最相似的艺术品。
- 从 met 的对象 api 加载有关这些艺术品的详细信息,并通过个性化推荐来增强页面。
瞧,个性化推荐:

好吧,让我们来分解一下。
创建数据集
met 的原始数据集是一个包含很多列的 csv,如下所示:
object number,is highlight,is timeline work,is public domain,object id,gallery number,department,accessionyear,object name,title,culture,period,dynasty,reign,portfolio,constituent id,artist role,artist prefix,artist display name,artist display bio,artist suffix,artist alpha sort,artist nationality,artist begin date,artist end date,artist gender,artist ulan url,artist wikidata url,object date,object begin date,object end date,medium,dimensions,credit line,geography type,city,state,county,country,region,subregion,locale,locus,excavation,river,classification,rights and reproduction,link resource,object wikidata url,metadata date,repository,tags,tags aat url,tags wikidata url
1979.486.1,false,false,false,1,,the american wing,1979,coin,one-dollar liberty head coin,,,,,,16429,maker," ",james barton longacre,"american, delaware county, pennsylvania 1794–1869 philadelphia, pennsylvania"," ","longacre, james barton",american,1794 ,1869 ,,http://vocab.getty.edu/page/ulan/500011409,https://www.wikidata.org/wiki/q3806459,1853,1853,1853,gold,dimensions unavailable,"gift of heinz l. stoppelmann, 1979",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/1,,,"metropolitan museum of art, new york, ny",,,
1980.264.5,false,false,false,2,,the american wing,1980,coin,ten-dollar liberty head coin,,,,,,107,maker," ",christian gobrecht,1785–1844," ","gobrecht, christian",american,1785 ,1844 ,,http://vocab.getty.edu/page/ulan/500077295,https://www.wikidata.org/wiki/q5109648,1901,1901,1901,gold,dimensions unavailable,"gift of heinz l. stoppelmann, 1980",,,,,,,,,,,,,,http://www.metmuseum.org/art/collection/search/2,,,"metropolitan museum of art, new york, ny",,,
足够简单,可以将其转换为两列,一个 id 和一个字符串:
id,description
1,"one-dollar liberty head coin; type: coin; artist: james barton longacre; medium: gold; date: 1853; credit: gift of heinz l. stoppelmann, 1979"
2,"ten-dollar liberty head coin; type: coin; artist: christian gobrecht; medium: gold; date: 1901; credit: gift of heinz l. stoppelmann, 1980"
3,"two-and-a-half dollar coin; type: coin; medium: gold; date: 1927; credit: gift of c. ruxton love jr., 1967"
现在我们可以使用 hugging face ai 工具集中的 transformer 包,并生成每个描述的嵌入。 我们使用sentence-transformers/all-minilm-l12-v2模型,并使用主成分分析(pca)将结果向量减少到5维。 这会给你类似的东西:
[
{
"id": 1,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
{
"id": 2,
"vector": [ -0.005544120445847511, -0.030924081802368164, 0.008597176522016525, 0.20186401903629303, 0.0578165128827095 ]
},
…
]
我们有 50 万个这样的数据集,因此不可能将整个数据集存储在边缘应用程序的内存中。 我们希望对这些数据进行自定义类型的相似性搜索,这是传统键值存储所不提供的。由于我们正在构建实时体验,因此我们也确实希望避免一次搜索 50 万个向量。
那么,让我们对数据进行分区。 我们可以使用 kmeans 聚类来对彼此相似的向量进行分组。 我们将数据分成 500 个不同大小的簇,并为每个簇计算一个称为“质心向量”的中心点。 如果您以二维方式绘制此向量空间并放大,它可能看起来有点像这样:
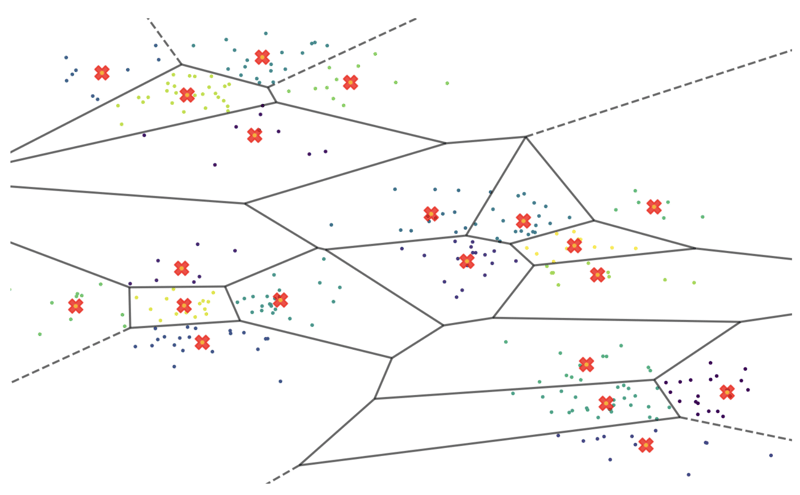
红十字是每个向量簇的数学中心点,称为质心。它们可以像我们 50 万向量空间的寻路器一样工作。例如,如果我们想找到与给定向量 a 最相似的 10 个向量,我们可以首先寻找最近的质心(在 500 个质心中),然后仅在其相应的簇内进行搜索——这是一个更易于管理的区域!
现在我们有 500 个小数据集和一个将质心点映射到相关数据集的索引。 接下来,为了实现实时性能,我们想要预编译搜索图,这样我们就不需要在运行时初始化和构造它们,并且可以使用尽可能少的cpu时间。 一种非常快速的最近邻算法是分层可导航小世界(hnsw),它有一个纯 rust 实现,我们用它来编写我们的边缘应用程序。 因此,我们编写了一个小型独立 rust 应用程序来为每个数据集构建 hnsw 图结构,然后使用 bincode 将实例化结构的内存导出到二进制 blob。
现在,这些二进制 blob 可以加载到 kv 存储中,针对集群索引进行键控,并且集群索引可以包含在我们的边缘应用程序中。
这种架构允许我们按需将部分搜索索引加载到内存中。而且由于我们永远不需要一次搜索超过几千个向量,因此我们的搜索将始终廉价且快速。
构建边缘应用程序
我们在边缘运行的应用程序需要处理多种类型的请求:
- html 页面: 我们从 metmuseum.org 获取这些内容并转换响应以添加额外的前端
- fastly 脚本和样式资源 由这些额外标签引用,我们可以直接从边缘应用程序的二进制文件中提供服务。
- 推荐端点,生成并返回推荐 ** 所有其他(非 html)请求: 图像以及大都会艺术博物馆自己的脚本和样式表,我们直接从其域代理,无需更改。
我们最初用 javascript 构建了这个应用程序,但最终将推荐部分移植到 rust,因为我们喜欢即时距离的 hnsw 实现。
客户端 javascript 做了一些有趣的事情:
- 使用 intersectionobserver,当用户将页面向下滚动到相关对象部分时,我们会触发一个事件。这是一个超级高效的 api,比使用 onscroll 等旧方法要好得多。
- 获取我们的特别推荐 api 端点(然后我们可以在边缘处理并返回对象信息)
- 使用客户端函数内置的模板编写一些 html
- 将该 html 附加到页面并将交叉观察器移动到新元素,以便当您滚动浏览建议时,我们会不断加载更多内容。
这样,我们可以在不调用我们的推荐算法的情况下提供主要的 html 有效负载,但推荐的提供速度足够快,我们可以在您滚动时加载它们,并且当您到达它们时它们几乎肯定会在那里。
我喜欢以这种方式做事,因为尽快向用户提供第一个首屏视图绝对是最重要的。 除非滚动才能看到的任何内容都可以稍后加载,特别是如果它是复杂的个性化内容 - 如果用户不打算滚动,则生成它是没有意义的。
结束语
现在您拥有了两全其美的优势:能够提供高度个性化的内容,几乎不需要对源进行任何阻塞提取,并且优化的 html 有效负载可以以令人难以置信的速度呈现,从而使您的应用程序能够有效地享受无限的可扩展性和近乎完美的弹性.
这不是一个完美的解决方案。 如果 fastly 提供更多更高级别的功能来通过查询机制而不是简单的键查找来公开边缘数据(让我们知道这是否对您有帮助!),并且这种特定机制有明显的缺陷 - 如果我对以下方面有单独的兴趣两个或更多非常不同的东西(比如19世纪的油画和古罗马双耳瓶)我会得到建议,这将是这些之间的理论语义“中间点”,而不是一个非常有用的结果。
不过,希望这证明了一个原则,即弄清楚如何在边缘工作通常会在可扩展性、性能和弹性方面带来巨大的好处。
让我们知道您在community.fastly.com 上构建了什么!



