标签编码是机器学习中最常用的技术之一。它用于将分类数据转换为数字形式。因此,数据可以拟合到模型中。
让我们了解为什么我们使用标签编码。想象一下,数据包含字符串 形式的基本列。但是,您无法将这些数据放入模型中,因为建模仅适用于数值数据,我们该怎么办?这是一种挽救生命的技术,当我们准备好数据进行拟合时,它会在预处理步骤中进行评估,这就是标签编码.
我们将使用scikit-learn库中的iris数据集来了解标签编码器的工作原理。确保您安装了以下库。
pandas
scikit-learn
要安装为库,请运行以下命令:
$ python install -u pandas scikit-learn
现在打开 google colab notebook,开始编码和学习 label encoder。
让我们编码吧
- 首先导入以下库:
import pandas as pd
from sklearn import preprocessing
- 导入iris数据集,并初始化以供使用:
from sklearn.datasets import load_iris
iris = load_iris()
- 现在,我们需要选择我们想要的数据编码,我们将对鸢尾花的物种名称进行编码。
species = iris.target_names
print(species)
输出:
array(['setosa', 'versicolor', 'virginica'], dtype='<u10><ul>
<li>让我们实例化来自<em>预处理</em>的类<em>labelencoder</em>:
</li>
</ul>
<pre class="brush:php;toolbar:false">label_encoder = preprocessing.labelencoder()
- 现在,我们准备使用标签编码器来拟合数据:
label_encoder.fit(species)
你将输出类似这样的内容:
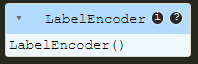
如果得到此输出,则说明您已成功拟合数据。但是,问题是如何找出分配给每个物种的值以及分配的顺序。
标签编码器适合数据的顺序存储在classes_属性中。编码从0开始到data_length-1.
label_encoder.classes_
输出:
array(['setosa', 'versicolor', 'virginica'], dtype='<u10><p>标签编码器会自动对数据进行排序,并从左侧开始编码。这里:<br></p>
<pre class="brush:php;toolbar:false">setosa -> 0
versicolor -> 1
virginica -> 2
- 现在,让我们测试一下拟合的数据。我们将改造山鸢尾品种。
label_encoder.transform(['setosa'])
输出:数组([0])
再说一次,如果你改造维吉尼亚币。
label_encoder.transform(['virginica'])
输出:数组([2])
您还可以输入物种列表,例如["setosa", "virginica"]
scikit learn 标签编码器文档 >>>



